

Витторио Феррари — профессор Эдинбургского университета и научный сотрудник Google (глава исследовательской группы CALVIN по визуальному обучению) — занимается созданием компьютерной модели, которая позволит с минимальным человеческим вмешательством распознавать объекты и действия на изображении. Мы записали выступление Витторио Феррари на саммите Machine Can See 2018 в Москве, — о том, как работает человеко-машинное сотрудничество, и почему за компьютерным зрением стоит колоссальное будущее.
На распознавание миллиона кадров уйдет 160 лет
Понимание сцен — ключевая задача компьютерного зрения. Компьютер анализирует изображения или видео и классифицирует всю сцену по ее категории, это напоминает игру в теннис. Затем он распознает объекты в сцене по классам и локализует их, заключив в прямоугольник или контур. Объекты находятся напротив поверхностей, например, теннисный корт и стена, которые также распознаются и локализуются.
Распознавание объектов — сложный процесс из-за большого количества вариаций. В идеале компьютер анализирует сцену и выясняет все визуальные элементы и их взаимоотношения. Реализация визуального распознавания рождает множество его применений. Например, создание робота, который перемещается по комнате и подбирает предметы, делает уборку за вас. Самое распространенное применение визуального распознавания — беспилотные автомобили.
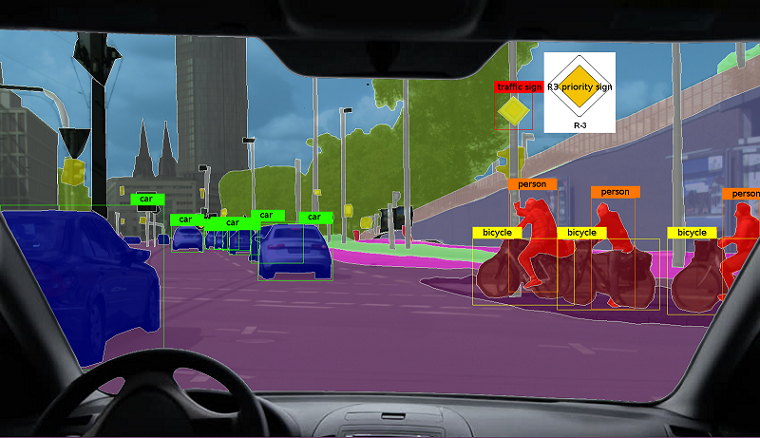
Проблема определения объекта в реальном мире решена с помощью математических моделей закрытого типа. Возьмем объект — книгу о Гарри Поттере. Когда вы переносите ее в реальный мир, она меняет внешний вид из-за освещения и масштаба. Точка зрения меняет картину распределения пикселей на книге. На изображении есть другие вещи, которые загораживают книгу, и беспорядок на заднем плане. Если объект гибкий, определение становится сложнее.
Машинное обучение вступает в игру, когда распознает целый класс объектов. Чтобы распознать все автомобили в реальном мире, математическая модель закрытого типа не подойдет. Автомобиль «Формулы 1» отличается от автомобиля Smart. Нет такой модели, которая бы описала трансформацию одной формы в другую.

Это происходит с помощью ручных пояснений. Обычно — около 1000 примеров для каждого класса как минимум. Для создания модели, способной заключать предмет в прямоугольник, необходимо начертить его вручную. Согласно базе данных ImageNet — на один прямоугольник уходит 26 секунд. Мы сократили время до 7–10 секунд. Для модели, локализующей объект с помощью контура, необходимо его отметить на изображениях. Согласно базе данных COCO это займет 80 секунд на контур. Чтобы определить все объекты и фоновые области с точностью до пикселя, мы потратили на COCO-Stuff 1000 секунд на одно изображение. На миллион подобных аннотирований уйдет 160 лет, в течение которых один человек будет щелкать по экрану снова и снова.
Human-machine collaboration
Полностью контролируемое обучение — самое распространенное. При нем данные аннотируются в зависимости от ожидаемого результата на выходе. Если нужен детектор объектов (реагирует на движение или распознает объекты — «Хайтек») — необходимо рисовать прямоугольники, если полная модель сегментации — подробно аннотировать изображения.
При слабо контролируемом обучении компьютер занимается авто-аннотированием, рисованием. Вы просто помечаете каждое изображение набором слов, которые описывают предметы на нем. Детектором является весь список объектов на изображении, но вы не отмечаете их местонахождение. Модель работает хуже, чем при полностью контролируемом обучении.

Сотрудничество человека и машины (human-machine collaboration — «Хайтек») — промежуточный вариант между двумя вариантами обучения. Вы начинаете со слабо контролируемого обучения. Компьютер сам реконструирует данные для обучения, но в процесс вмешивается человек и предоставляет информацию: рисует прямоугольники или производит комментирование.
Метки на уровне изображений (image-level labels — «Хайтек») — самый распространенный способ получения слабо контролируемого обучения. Люди щелкают один раз посередине объекта и позволяют компьютеру создать прямоугольник.
Цель передачи знаний (knowledge transfer — «Хайтек») — улучшить детекторы классов без прямоугольников. Происходит перенос знаний от классов, имеющих ограничительные прямоугольники, к тем, которые их не имеют.

Интеллектуальный голосовой помощник «Алиса» компании «Яндекс» уже научился «видеть» благодаря компьютерному зрению. Если показать «Алисе» фотографию, она поймет, что на ней изображено. С помощью нового функционала помощник «узнает» животных, здания, людей и произведения искусства. Если на изображении есть текст, «Алиса» прочтет его и, если это иностранный язык, переведет.
Как научить детектор распознавать объект
Слабо контролируемое обучение используется при обучении детектора распознавать объект. Например, мотоцикл. Стандарт слабого контроля — получение детектора, заключающего мотоцикл в прямоугольник. В передаче знаний (knowledge transfer) у вас есть исходный набор с различными исходными классами, для которых имеются аннотации с ограничительными прямоугольниками. Вы хотите передать знания от этого набора данных другому, лишь с метками изображений. Метки на уровне изображений (image-level labels) очень быстро сделать — примерно 2 секунды на метку. Но слабо контролируемое обучение само по себе плохо работает. Обычно это 50–60% от качества модели, обученной на вручную нарисованных прямоугольниках.

Обучение на различных примерах (multiple-instance learning — «Хайтек») — один из методов применения слабо контролируемого обучения. У вас есть изображения с мотоциклами и без них. Вы раскладываете изображения на набор «предложений» объектов (object proposals — «Хайтек») — тысячи окон, покрывающих предположительно все объекты на изображении. Среди положительных примеров изображений есть хотя бы одно положительное «предложение», негативные содержат только негативные «предложения». Цель обучения на различных примерах — найти истинно верные «предложения», чтобы локализовать объект и обучить классификатор окон (window classifier — «Хайтек»).
Как лучше осуществлять «передачу знаний»
Исходные классы необходимо организовывать в семантическую иерархию. К примеру: жираф — это животное, животное — это объект. Затем мы обучаем один детектор нейросети разбивать весь набор источников на различные классы, приведя их в иерархию. Жираф, например, становится примером обучения для класса животных и класса предметов. Детектор нового класса создаст одиночную партию «предложений» объектов высокого качества и присвоит им показатель вероятности для всех классов исходного набора. То есть у каждого будет показатель вероятности жирафа, животного и объекта. Эту модель легко использовать для «игры» с передачей знаний (knowledge transfer), чтобы быстро проводить эксперименты.
Когда вы делаете эксперименты, нужно быть очень осторожным и делать их правильно, иначе вы замусорите данные. Мы использовали базу данных ImageNet detection challenge на настройках компании LSDA из Беркли. Первые 100 классов имели прямоугольники — это наш исходный набор. Целевой набор из 100 классов содержит «метки на уровне изображений» (image-level labels). Задача передать знания от первого набора второму. Мы рисуем прямоугольники во втором наборе, а на этих прямоугольниках обучаем детектор и оцениваем, как он работает. Если вы будете использовать только «предложения» объектов, которые создает ваш исходный детектор — это даст около 30% верных локализаций
Если вы добавите любую функцию передачи знаний от любого уровня, процент корректности взлетает до 70%. Передача знаний от более общего класса работает немного лучше, чем более интуитивная передача от родственного класса. То есть передача от класса велосипедов классу мотоциклов работает хуже, чем от класса предметов классу мотоциклов.
Добавление функции обучения у более общего класса (class generic learn function — «Хайтек») создает большой рост корректности. Возьмем полностью контролируемое обучение с вручную нарисованными прямоугольниками за 100%. Использование нашего метода даст 80% от этого. Без «передачи знаний» вы получите примерно 55%.
Интеллектуальный диалог аннотаций
Последовательность верификаций прямоугольников (box verification series — «Хайтек») — когда есть детектор, который называет форму — прямоугольник, а человек просто говорит, правильно ли он отмечает предмет. Если прямоугольник не покрывает предмет целиком, человек говорит «нет», и компьютер выдвигает другое «предложение». Это гораздо эффективнее, чем рисовать вручную. Но работает не всегда, так как зависит от сложности изображения.

Если у вас более сильный детектор — вы предпочитаете верификацию, поскольку вы получаете правильный ответ за несколько вопросов. А если у вас более слабый детектор, то лучше рисовать, поскольку будет много вопросов. Если вам нужны очень точные прямоугольники, то опять рисование. Потребуется больше вопросов, чтобы получить точный прямоугольник.
Intelligent Annotation Dialogue (IAD, интеллектуальный диалог аннотаций — «Хайтек») подразумевает, что компьютер оценивает все «предложения», а человек обучает агента искать оптимальную последовательность действий. Это означает аннотирование прямоугольника за минимальное количество времени. Агент свободно выбирает между верификацией и рисованием, учитывая свойства изображения. Смысл в том, чтобы найти для агента момент, когда он сдается: не предлагает прямоугольник, а просит нарисовать его.
Первый тип агента основан на моделировании ожидаемого времени аннотации. Если вы знаете, как быстро рисуете прямоугольник, как быстро верифицируете, и у вас есть машина, предсказывающая вероятность принятия человеком прямоугольника, то реально вычислить время для любого возможного диалога. В конце вам потребуется предсказатель принятия классификатора (acceptance classifier predictor — «Хайтек»). Работает агент по правилу: необходимо верифицировать все прямоугольники, у которых вероятность принятия больше чем соотношение времени верификации к времени рисования.
Второй тип агента работает без моделирования ожидаемого времени аннотирования в процессе обучения в «среде». Средой здесь будут аннотаторы (люди, которые занимаются аннотированием — «Хайтек») и особенности прямоугольников. Он смотрит на прямоугольник и задается вопросом: «должен ли я попросить его верифицировать», затем он смотрит на следующий и т.д.

В реальном мире вам необходим ни слабый детектор, ни сильный. В начале у нас был слабый детектор, потому что мало данных, 1% от общего числа. Мы постепенно улучшали детектор, и каждые 3%, 6%, 12% и так далее до 100% мы обучали новый детектор и обновляли агента на базе наших собственных данных. Наш агент справляется с этим лучше, чем последовательность верификаций прямоугольников (box verification series) и даже лучше, чем новая быстрая версия рисования. На это уходит примерно 3.5 секунды на прямоугольник. Производительность детекторов, которые выходят из этого процесса, составляет 98% от производительности детектора, обученного с нарисованными вручную прямоугольниками
«Мы наделили человека-аннотатора полномочиями»
Мы предлагаем подвижное аннотирование (Fluid Annotation — «Хайтек»). У вас есть изображение, но вы начинаете с интерпретации сцены, автоматически созданной компьютерной моделью. Затем аннотатор может редактировать ее. И лишь через несколько десятков щелчков вы получаете приблизительную аннотацию, которая достаточно хороша. В традиционной системе аннотирования LabelMe вы вручную рисуете многоугольник. Примерно по 80 секунд на каждый. Полностью аннотированное изображение с прорисованными контурами объектов и фоновых областей вы получите через 300 щелчков.
Наш объединенный интерфейс позволяет ставить метки классов, рисовать многоугольники областей не последовательно, а одновременно. Обычно компьютер выбирает последовательность и предлагает: нарисуй этот прямоугольник, верифицируй этот. Мы наделили полномочиями аннотатора и показываем ему подходящую интерпретацию сцены. Аннотатор видит с первого взгляда, где есть ошибки, и он выбирает и исправляет самые очевидные ошибки. Аннотатор фокусируется на том, что еще неизвестно машине, это экономит много времени.
От аннотатора лишь требуется щелкнуть несколько раз и найти одеяло, бум — эта область стала одеялом. Мы обучили модель Mask R-CNN. Она производит примерно тысячу сегментов на изображении вместе с метками классов и вероятностью того, что они корректны. Из сегментов мы формируем наиболее подходящую интерпретацию сцены. Аннотатор может переназначить сегмент, поменять метку и сказать: на самом деле это не человек, это одеяло.
Наш метод примерно в 3 раза более эффективен, чем стандартный интерфейс. Затраченное время также примерно в 3 раза меньше, чем при рисовании многоугольников.
Редакция «Хайтек» благодарит саммит Machine Can See, организованный VisionLabs при поддержке «Сбербанк» и Sistema_VC, за помощь в подготовке материала.