

Цес Снук — профессор Амстердамского университета и директор QUVA (лаборатории глубокого обучения машин). Он занимается технологией компьютерного зрения, обучает роботов не просто фиксировать изображение, но и распознавать, что на нем происходит. Уже сейчас ИИ может различить на видео кошку и собаку, понять, где действие — будь то дорожное движение или спортивные состязания. «Хайтек» поговорил с ученым на саммите Machine Can See 2018 и выяснил, насколько опасно то, что машина начнет не только думать, но и «видеть».
Видео — это носитель информации будущего
— Что такое компьютерное зрение, и почему оно так важно для развития современных технологий?
— Компьютерное зрение — это технология, которая позволяет машинам видеть и дает им возможность воспринимать полученную информацию. Почему это важно? Самый важный орган чувств для человека — это глаза, через них мы получаем большую часть информации. Видео — это носитель информации будущего. Люди постарше используют текст, а для молодежи поисковым средством по умолчанию являются ресурсы вроде YouTube или Snapchat, а не Google.
— Поэтому вы так много работаете с видео на YouTube?
— Да, и потому что они легко доступны. При работе с ними нет никаких проблем с личными данными или авторским правом.

— А что будет с компьютерным зрением в будущем?
— Существует много областей применения компьютерного зрения, в частности, беспилотные автомобили и здравоохранение. Например, медицинская визуализация: когда вы можете сфотографировать пятна на вашей коже, чтобы узнать являются ли они проявлением рака или нет. Как это происходит сейчас? Вы идете в больницу, врач смотрит на пятна на коже, и его заключение весьма субъективно. Конечно, есть определенные критерии для диагноза, но чаще всего — это «ложная тревога».
Я не говорю, что компьютеры заменят врачей. В ситуации, когда вы сомневаетесь или боитесь идти ко врачу, вам все же лучше к нему обратиться. Это может спасти вам жизнь.
Мы не можем до конца представить всех возможностей компьютерного зрения. Сейчас оно используется при поиске изображений или видео в интернете, в поисковых системах. Очень сложно предсказывать будущее, но у этой технологии есть потенциал во множестве областей.
— Вы говорили, что к 2022 году в мире будет 45 миллиардов камер. Что дальше?
— В данный момент мы видим, как быстро развиваются технологии. Посмотрите, какими маленькими могут быть современные устройства с камерой и новейшим программным обеспечением. Поэтому нас ждет эпоха интернета вещей, и уже не за горами появление 5G. Так что скоро станет еще проще записывать видео и передавать его по беспроводной сети.
Другой вопрос, что нам делать со всей этой информацией. Мы не собираемся хранить ее вечно, но полезно иметь доступ к ней. Это позволит оглянуться назад, получить автоматический ответ на запрос: что увидела программа в нужный момент времени.
Вот у вас есть камера, в которой есть все необходимые технологии и достаточный объем памяти. Вам не придется посылать информацию в «облако», а приватность будет в безопасности. Такая камера позволит увидеть определенные вещи, которые недоступны человеческому глазу и предупредить об опасности.

— Имеете в виду, что камеры могут захватывать информацию за пределами визуального спектра. Это как?
— К примеру, есть инфракрасное излучение, которое мы не можем видеть, но для камеры это не важно. Есть гиперспектральные камеры, которые воспринимают информацию за пределами видимого спектра. Они могут видеть больше, поскольку не ограничены возможностями человеческого глаза
«Лет через 5 в интернете вы легко найдете все изображения с вашим лицом»
— Как компьютерное зрение изменит существующие способы использования камер, такие как видеотрансляции, соцсети, телевидение?
— Я думаю, сегодня люди обеспокоены тем, что текст, который они печатают в интернете, остается там. Звучит пугающе, что к этому тексту приписывается ваше имя. Люди не так осторожны с размещением фото и видео в интернете. Потому что еще 5 лет назад наши возможности работы с фотографиями и видеозаписями были сильно ограничены, но скоро в интернете вы легко найдете все изображения с вашим лицом. Это позволит вывести различную статистическую информацию, например, как часто вы курите. И самое важное — у каждого будет доступ к этой информации.

Каждую секунду за человечеством наблюдают миллионы камер — на улице, в аэропортах, в банках, магазинах и кинотеатрах. Они не просто фиксируют изображение, но и идентифицируют человека. С помощью компьютерного зрения машина получает информацию о размерах и форме объекта, определяет его тип.
Алгоритм распознавания лиц построен на принципе машинного обучения и нейронных сетях. Ведущий исследователь компании VisionLabs Сергей Миляев объясняет: для распознавания лиц нейронная сеть извлекает индивидуальные признаки лица из изображения. При этом на результат не влияют — макияж, освещение, волосы, возраст и даже ориентация головы человека в пространстве.
Но воспроизвести человеческое зрение машина все равно не может. Она лишь выполняет моделирование некоторых его аспектов.
— Это говорит об определенных проблемах приватности.
— Да, и к тому же встает вопрос: кто обладает этой информацией и имеет право на ее использование? Так что я думаю, важным является законодательный вопрос. Сейчас технология действительно опережает законы, и я думаю необходимы изменения в законодательстве, чтобы регулировать добросовестное использование информации.
«Если на видео холодильник, машина поймет, что действие происходит на кухне»
— Что такое глубокое обучение машин для автоматического обнаружения действий в видеопотоке?
— Сейчас подход заключается в том, чтобы научить машину на множестве примеров распознавать действия, — как-то так.
При классификации изображений с кошками или собаками происходит примерно такая история. Во многих разработках видео рассматривается как набор последовательных изображений. Сперва действия классифицируются на каждой картинке в отдельности. А затем объединяются во времени. Это самый базовый поход. В ближайшем будущем мы начнем учитывать особенности видео как носителя информации, то есть определять длительные взаимодействия объектов. Хотя, если честно, мы еще не знаем, как это сделать.

— Что такое пространственно-временная локализация действий в видео. Как она достигается?
— Есть два основных подхода. Первый подход заключается в генерировании так называемых proposals (области на изображении, в которых предполагается наличие объекта — «Хайтек»). Из них, в свою очередь, генерируются тысячи так называемых tubes (tubes или tubelets — совокупности proposals, объединенные во времени — «Хайтек»), которые проходят через видео. А затем классификатор старается предугадать вероятность, с которой искомое действие заключено в одном из них. После этого классификатор выбирает «туннель» с самой высокой вероятностью.
Второй подход заключается в том, чтобы взять изображение из видео и попытаться локализовать действие, заключив его в box (рамка, ограничивающая объект на изображении — «Хайтек»). Для каждого изображения в отдельности вы делаете классификацию. Затем появляется множество индивидуальных рамок, которые вы пытаетесь соединить во времени, чтобы найти схожесть или пересечения.
Это два наиболее распространенных решения. Также существует подход, который использует рекуррентные нейронные сети (вид нейронных сетей, где связи между элементами образуют направленную последовательность, благодаря этому появляется возможность обрабатывать серии событий во времени или последовательные пространственные цепочки — «Хайтек»). При этом подходе нейросеть обучают находить определенное действие, например, игру в теннис. Затем сеть автоматически учится тому, какое местонахождение наиболее подходит к классификации, и автоматически определяет его.
— Вы много говорите об извлечении невидимых запросов с использованием семантической памяти, не могли бы вы подробно на этом остановиться? Как это происходит?
— Не таких уж невидимых! Скорее запросов, которые не использовались до этого. Мы также называем это zero-shot retrieval (поиск нулевого кадра — поиск объектов, которых не было в обучающей выборке — «Хайтек»).
Есть алгоритм классификации кошек и тысячи изображений. Вы запустили свой классификатор тысячу раз и каждое изображение будет иметь определенную вероятность, что на нем есть кошка. Изображение с самой высокой вероятностью должно содержать кошку, но такой алгоритм требует обучения на сотнях положительных и отрицательных примерах. Так что если вы хотите узнать ответ для любого запроса, то алгоритм не будет работать, потому что для каждого запроса нужны примеры.
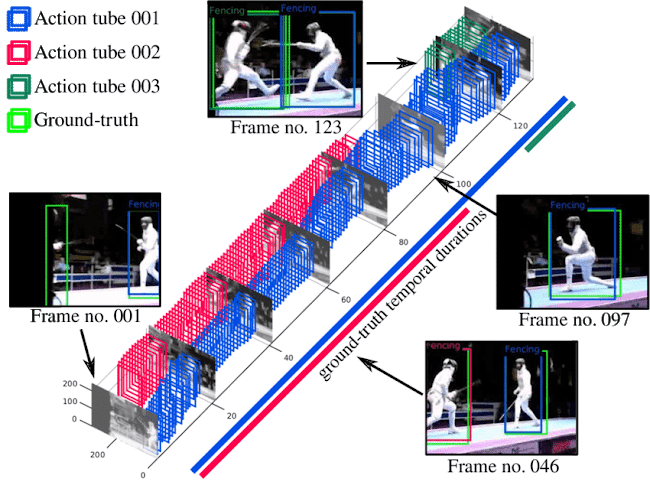
Автоматическое распознавание видов деятельности, к примеру, гольф и поло. Их пространственно-временную локализацию показывает красный tube, а вероятность нахождения объекта и местоположения — зеленый и синий, соответственно.

Вы также можете сказать: если у меня есть тысячи таких классификаторов кошек, собак, кухонь и так далее, и я представлю каждое изображение в каждом видео при помощи тысячи этих оценок, у меня будет что-то вроде текстовой репрезентации. Но она ограничена, поскольку мы знаем всего лишь тысячу слов.
Однако есть особые приемы в текстовом анализе, которые делают текстовую репрезентацию более богатой. К примеру, используя Word2vec (программа, которая анализирует семантику естественных языков. Она представляет слова в виде векторов, основываясь на их контекстной близости — «Хайтек»). Она позволяет находить ассоциации между словами: несмотря на то, что у вас есть тысяча классификаторов в репертуаре, используя ассоциации в тексте, вы можете установить, что кошки и собаки — это типичные домашние животные, и что есть другие домашние животные. Это сделает вашу репрезентацию гораздо богаче. Если у вас есть случайный запрос, то вы сможете узнать какая репрезентация наиболее подходит к вашему запросу, без дополнительного обучения на примерах.
Это и есть принцип объединения объектов для распознавания сцен. Например, на кухне обычно находится холодильник. И если мой классификатор холодильника дает этому видео высокий балл, то, скорее всего, действие происходит на кухне.
— Что этот принцип даст машинам?
— Он уменьшает объем данных для обучения. Это очень важно, поскольку в данный момент ведущие технологические компании, которым принадлежит большая часть информации, лидируют в этой области. Огромные объемы данных используют Google и Facebook, чтобы делать свои алгоритмы все лучше и лучше. Поэтому новым компаниям так сложно выйти на рынок — у них нет доступа к этой информации. Мы не хотим зависеть от крупных компаний, которые владеют всеми этими данными. Так что, создавая алгоритмы, менее зависимые от количества данных, мы улучшаем экономическую систему
«Меня пугает, что все данные будут принадлежать Google»
— Мы начали наш разговор с будущего, что в мире 45 млрд камер. Это очень серьезная цифра. А вы хотите обучить машины не только наблюдать, но и анализировать. Многие и так боятся так называемого «восстания машин». Не означает ли это, что в будущем не будет приватности, мы будем все под наблюдением?
— Я надеюсь, что нет. То есть, конечно, к этому все идет, и нам всем необходимо с этим что-то делать.

— Значит это вопрос скорее законодательный: будем ли мы под наблюдением «большого брата»?
— Все сводится к тому, кто владеет данными. Если они централизованно принадлежат государству, то это пугает меня. Но также меня будет пугать, что все данные будут принадлежать Google.
— Но ведь они могут быть использованы как для благородных целей, так и напротив?
— Да, мой любимый пример — нож для хлеба — замечательная инновация. С помощью него вы можете нарезать хлеб на ровные и тонкие кусочки, но также можете убить им кого-нибудь. Так что технологии в неправильных руках — это опасно.
— Как вы думаете, как ученый, работающий с нейросетями: возможно ли в ближайшие десятилетия создать на основе нейросетей искусственный интеллект, наделенный сознанием?
— Я не так оптимистичен. Мы делаем большой прогресс, сейчас уже Google DeepMind (британская компания, занимающаяся искусственным интеллектом — «Хайтек») создала программу, способную победить мирового чемпиона по игре в Го. Это фантастика! Робот победил человека в столь сложной и интуитивной игре, но эта машина играет лишь в Го, она не способна ничего больше делать. Она не может определить кошку на изображении, для этого нужен уже другой ИИ. Есть еще множество вещей, которые машины не способны делать. Здорово, что мы достигли такого прогресса, но не стоит его преувеличивать.
— В массовой культуре популярен сюжет создания машины, наделенной самосознанием. Поэтому многие люди думают, что в скором времени она может появиться.
— Я так не думаю. Машины, которые сейчас создаются, не похожи на людей. Люди всегда найдут преимущество в любой технологии. Так происходило с каждым великим изобретением. И главная их цель — технологии позволяют создавать новые вещи.
Редакция «Хайтек» благодарит саммит Machine Can See, организованный VisionLabs при поддержке «Сбербанк» и Sistema_VC, за помощь в подготовке материала.