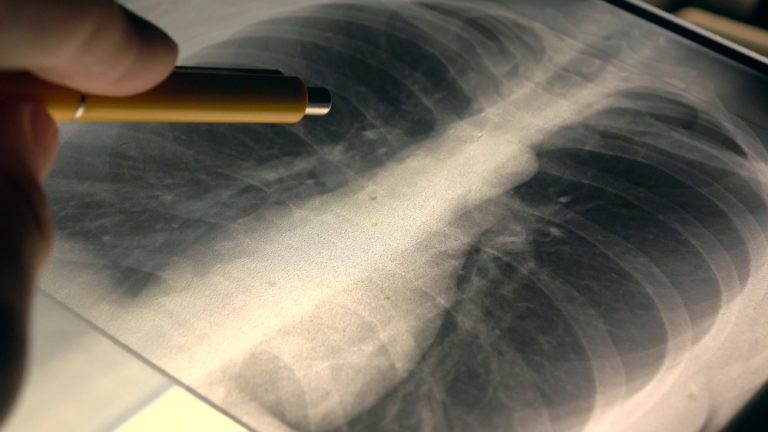
Google отменил проект по публикации датасета из 100 тыс. рентгеновских снимков грудной клетки, который планировалось использовать для обучения искусственного интеллекта. Причиной оказалось то, что в данных содержалась личная информация пациентов, пишет The Washington Post.
Инцидент произошел в 2017 году — тогда Google в течение нескольких месяцев вместе с Национальным институтом здравоохранения США (NIH) собирал крупнейший датасет из 100 тыс. рентгеновских снимков грудной клетки реальных пациентов.
По данным издания, Google и NIH вместе работали над обезличиванием данных, однако сотрудники компании спешили, чтобы уложиться в установленный срок. В результате на снимках остались даты, в которые они были сделаны, а также украшения пациентов, которые те забыли снять перед процедурой.
В разговоре с изданием представитель Google сообщил, что компания не только отказалась от публикации датасета, но и не использовала данные при обучении своих систем искусственного интеллекта.
Мы уделяем большое внимание защите данных пациентов и стараемся обеспечить конфиденциальность и безопасность личной информации. В интересах защиты личных данных мы решили не размещать набор данных, собранных совместно с NIH. Мы удалили все изображения из наших внутренних систем и больше не работали с NIH.
Ранее Google объявила об обновлении своего раздела Health — сотрудники компании хотят превратить его в полноценный поиск для врачей, где можно будет найти медицинскую документацию. Кроме того, они будут подбирать проверенные факты под лженаучные видео.



