

Бионические протезы замещают утраченные конечности и выполняют их функции. Но когда речь заходит о кистях рук или пальцах, главные камни преткновения — это мелкая моторика и максимальная естественность жестов. Чтобы решить эти проблемы, студенты SkillFactory в ходе хакатона «прокачивали» прототип протеза на базе оптических датчиков «Моторики». Как это было и что получилось в итоге, рассказывают менторы хакатона Максим Балашов из «Моторики» и Андрей Рысистов из SkillFactory.
Работа над реальной задачей позволила студентам еще в процессе обучения приобрести практический опыт, а «Моторике» — проверить гипотезы и новые идеи.
Почему мы решили взяться за эту задачу
Каждый год в мире ампутируют конечности в среднем у 1 млн человек — и это не считая тех, кто уже родился без рук или ног. Далеко не у каждого есть доступ к хорошим протезам, но даже с самыми продвинутыми из них сложно добиться полной естественности движений.
Как работают бионические протезы и чем может помочь искусственный интеллект?
Основной принцип работы большинства протезов — это считывание электромиографического потенциала мышц, или, проще говоря, их напряжения. В гильзе, куда вставляется культя (часть конечности, оставшаяся после ампутации, или вследствие ее недоразвития (аплазии) — прим. ред.), устанавливаются два датчика, один отвечает за раскрытие кисти, другой — за закрытие. Пользователь напрягает мышцу, и срабатывает жест.
Бионические протезы делятся на два типа: однохватные — могут сжимать/разжимать кисть. Более сложные многохватные, помимо этого базового жеста, выполняют «уникальные» программируемые движения, потому что каждый палец может двигаться отдельно. Так, например, работает бионический протез Manifesto, в плане конструкции не уступающий последним моделям Boston Dynamics.
Например:

Однако остается проблема: чтобы выполнить жест, нужно сначала запрограммировать это, если его нет в быстром доступе, затем переключить жест (можно сделать через приложение в смартфоне или долгое удержание напряжения на датчике) и, наконец, открыть или закрыть жест путем напряжения мышцы.
То есть, помимо самого жеста, приходится выполнять довольно много дополнительных действий.


Бионический протез Manifesto — платформа для обучения ИИ
Поэтому, чтобы делать жесты без подготовки и сразу распознавать их как можно точнее, исследователи решили обратиться к искусственному интеллекту, а точнее — к ИИ-моделям, которые обучаются под каждого пользователя на его персональных данных.
Для более эффективной работы нейросети нужно иметь больше входных данных. «Моторика» разработала оптомиографические датчики, которые, в отличие от стандартных электромиографических, различают изменения не только в мышцах, но и в сухожилиях, суставах, кровотоках и коже. Широкий диапазон данных повышает точность, плавность и дает возможность использовать протез людям со слабым сигналом от мышц или вообще с его отсутствием. ИИ изучает, какие изменения показателей сопряжены с тем или иным жестом, и воспроизводит его, двигая микродвигателями нужных пальцев. Такая технологическая связка уже сейчас позволяет протезам выполнять определенные жесты.
Студенты, принимавшие участие в хакатоне, должны были усовершенствовать прототип ИИ-модели для системы управления протеза руки.
Как выглядел процесс хакатона
Участвовать в хакатоне могли все студенты и выпускники курса Data Science, которые отправили онлайн-заявку и обладали нужными навыками: это операции над массивами данных, навыки анализа данных, разведывательного анализа, построения моделей классификации и другие.
Всего было выбрано 44 участника, которых разбили на 8 команд по 3–6 человек: так, чтобы каждая была равносильна другим по опыту и навыкам ее членов. Участники команды самостоятельно распределяли роли внутри: тимлид, разработчик или проджект-менеджер.
У московских студентов была возможность приехать в лабораторию «Моторики» в Сколково, чтобы самостоятельно поучаствовать в процессе сбора данных с реального протеза. Выглядело это так: на руку участника устанавливали оптомиографические датчики, контроллер которых подключали к протезу. Затем протез делал серию жестов: открытая ладонь ✋, полный хват ✊, жест «пистолет» 👉, жест «ОК» 👌 и другие (всего их было 15), а пользователь их воспроизводил. Показания датчиков и жест, который выполнял пользователь в этот момент, фиксировались для каждого промежутка времени. Затем они оцифровывались в наборы данных, которые студенты использовали для решения задачи.
Задача заключалась в том, чтобы с использованием методов Data Science построить модели, которые по показаниям датчиков будут определять жесты, выполняемые пользователем.
Работа велась в формате трехэтапного хакатона: от простой задачи к сложной для плавного погружения в предметную область. Мы решили, что сперва дадим студентам общую картину, а потом постепенно будем усложнять постановку задачи. Третья уже была максимально приближена к «боевой».
После каждого этапа команды показывали свои решения, из которых мы отмечали лучшие. В процессе хакатона участники могли обращаться к нам — менторам — за консультациями. Мы также отвечали за разработку задач и критериев для оценки результатов. По окончании каждого этапа студенты получали от нас фидбэк, насколько их решение было актуальным и эффективным, а также комментарии относительно структуры кода и технических ошибок, связанных с машинным обучением.
Три этапа хакатона
В начале работы студенты получили данные и базовую модель как некий ориентир. Идея хакатона заключалась в том, чтобы команды улучшили результат базовой модели или приблизились к нему. Так мы хотели проверить, можно ли вообще улучшить нашу базовую модель.
На первом этапе командам нужно было классифицировать жесты по участку данных, то есть определить, из какого жеста в какой произошел переход.
Например, был совершен переход из нейтрального положения (открытая ладонь) в один из жестов и наоборот — из жеста в нейтральное положение. Нужно было обучить модель распознавать, какой был выполнен жест: сгиб/разгиб каждого пальца, жест «ОК» 👌🏻 и «пистолет» 👉🏻 и так далее.

На втором этапе требовалось классифицировать жест и определять его начало и окончание во времени. В итоге должна была получиться модель, которая распознает, как, в какой последовательности и с каким временным интервалом рука переходит от одного жеста к другому.
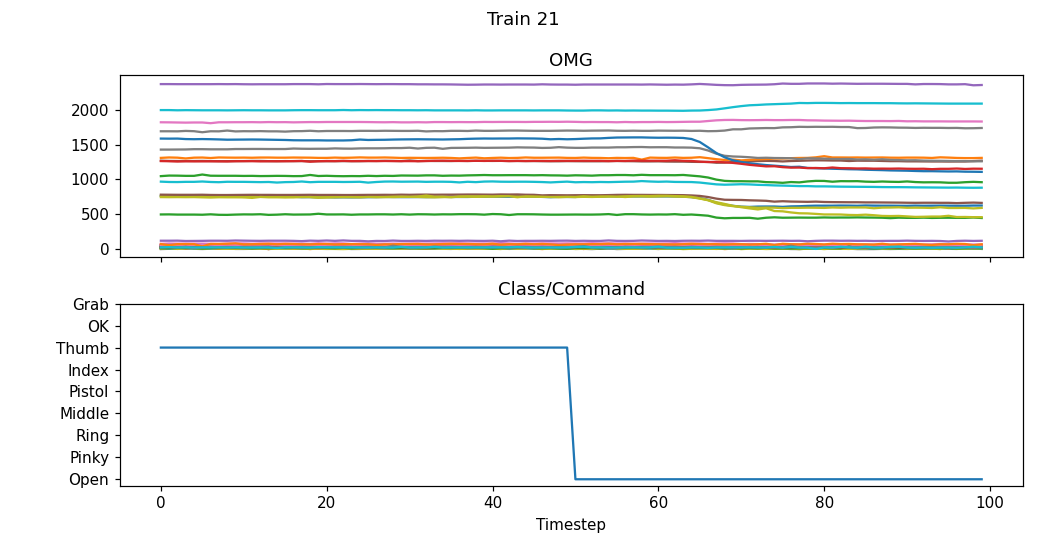
Если в первой задаче во всем исследуемом временном промежутке случился жест, то во второй задаче мы хотели, чтобы участники в каждый момент времени определили, какой выполнялся жест. Например, большой палец сгибался в течение определенного временного отрезка, а потом произошел переход к жесту открытой ладони.
На третьем этапе было необходимо сегментировать непрерывную запись на отдельные жесты с определением их начала и окончания во времени.
Задача качественно усложнилась. Теперь участники работали не с подготовленными наборами данных, а непрерывными сырыми данными. Требовалось самостоятельно разработать систему работы с ними: как их извлечь и как нарезать, чтобы потом обучать модели.

В первой и второй задачах мы брали один участок времени, то есть переход из одного жеста в другой, не больше. Но в реальности наша рука постоянно меняет свое положение, это происходит непрерывно, а не только в определенный промежуток времени. Мы переходим из одного жеста в другой, потом из этого жеста в третий, и так далее. И третья задача состояла в том, чтобы зафиксировать момент каждого перехода из одного жеста в другой и понять, в какой жест произошел переход, при этом жестов могло быть сколько угодно много.
Какие были результаты
Мы проводили хакатон с помощью платформы Kaggle. Решение проверялось алгоритмом, который оценивал качество построенной модели и ранжировал модели по степени точности, определяя результаты команд.
Результаты оценивались по стандартной для машинного обучения метрике F1-score: то есть по сочетанию полноты и точности полученных данных, для второй и третьей задачи метрика рассчитывалась для каждого момента времени.
Идеальным считалось решение, качество которого по метрике F1-score было максимально приближено к 1. У большинства участников по первым двум задачам метрика была близка к 1, они строили достаточно результативные модели, однако фактический потолок в рамках третьей задачи составлял всего 0,7.
При оценке работ мы учитывали и то, какой подход применяли студенты: насколько он отличался от базового алгоритма «Моторики», были ли найдены какие-то интересные закономерности, было ли решение универсальным с точки зрения потребляемых ресурсов, куда относятся используемая для решения оперативная память и скорость вычислительной мощности. Можно построить такую тяжеловесную модель, которая будет предсказывать идеально, но будет делать это в течение нескольких минут. Для человека с ампутированной рукой, носящего протез, ждать несколько минут, пока у него один палец начнет двигаться, совсем не оптимально. Система должна работать буквально в режиме реального времени с задержкой не более 100 мс.
По итогам хакатона практически все команды приблизили свой результат к базовой модели разработчиков и предложили некоторые интересные подходы. Модели, построенные участниками на первом и втором этапах, были результативными и хорошо работали в заданных условиях, помогли погрузиться в предметную область. В дальнейшем их будут тестировать в реальной ситуации. В третьей задаче участники предложили обновленные подходы к обработке данных перед тем, как отправлять их в модель, но эти гипотезы также нужно проанализировать и проверить. Если испытания пройдут успешно, полученные результаты могут быть использованы в дальнейшей работе.
Какие выводы мы сделали
Хакатон — это отличный пример того, как онлайн-школа движется от формата EdTech к ExperienceTech, когда теоретические знания обязательно дополняются практическими задачами от игроков рынка. Бизнес смог делегировать свои реальные задачи студентам и получить несколько новых интересных подходов, которые могут войти в релизную версию. Бизнес также получает потенциальных кандидатов, которые в процессе обучения погружаются в задачи индустрии.
Студенты отметили, что постепенное усложнение задач упростило переход от теоретической модели к реальной. Это позволило лучше погрузиться в проблему даже тем, у кого мало опыта в написании кода. Тем, кто раньше имел дело только с классическими моделями машинного обучения, было особенно интересно познакомиться с современными наработками в области глубокого обучения.
По окончании первого этапа мы увидели, что многим участникам не хватает навыков презентации результатов. Поэтому ввели дополнительный критерий оценки работ (культура кода), который включал в себя оформление кода по стандартам, документирование, следование правилам визуализации и текстовое сопровождение хода решения.
Из-за внешних обстоятельств время хакатона увеличилось с одного до двух месяцев, и мотивация некоторых участников снизилась, а другие вовсе вышли из проекта. В будущем мы постараемся оптимизировать время хакатона и рассчитывать его длительность более внимательно, чтобы сохранить высокий уровень вовлеченности и уделить больше внимания мотивации участника на каждом этапе.
Читать далее:
Ученые из зоны вечной мерзлоты: как они разрабатывают умную одежду и вакцину против рака
Ученые «обманули» время и отправили фотон в прошлое: как этот прорыв изменит физику