
Диффузионные нейросетевые модели появились в 2015 году, но набрали популярность только в 2020 году после работы Ho et al. Сегодня они достигли результатов исключительного качества в большинстве задач генерации и изменения изображений, включая генерацию изображений по тексту (text-to-image), изменение стиля изображения (style transfer), изменение деталей изображения (inpainting) или повышение разрешения (super-resolution).
Генеративно-состязательные сети и их недостатки
Всего лишь несколько лет назад state-of-the-art-моделями в этих задачах считались генеративно-состязательные нейросети (generative adversarial networks или GAN), которые были предложены в 2014 году в работе Goodfellow et al и были значительно улучшены за прошедшие девять лет. Например, модель StyleGAN 3 2021 года в точности сохраняет детали лица даже при сдвигах и поворотах, тогда как ее предшественники генерируют в этом случае «шумные» детали — к примеру, волосы, бороды или узоры на одежде. Профессионалы и энтузиасты удивлялись, насколько хорошо GAN могут генерировать фотографии несуществующих людей, животных или квартир.
Тем не менее, из-за состязательного характера модели GAN очень нестабильны в обучении, также они показывают не очень большое разнообразие типов изображений при генерации. К тому же они слабо применимы в задаче генерации изображений по тексту, хотя примеры этого существуют.


Бум диффузионных моделей
Диффузионные модели, напротив, обладают достаточной вариативностью сгенерированных изображений и достаточно стабильны. Их главный минус — это скорость обучения и генерации. Для обучения модели необходимы десятки или даже сотни видеокарт, а генерация изображения при помощи уже обученной модели занимает несколько секунд, в отличие от GAN, где счет идет на десятки миллисекунд.

Бум вокруг моделей диффузии подогревается выходом больших генеративных моделей text-to-image. Наверняка многие читатели видели результаты, сгенерированные DALL·E 2, MidJourney, Imagen или Stable Diffusion. Некоторые художники и иллюстраторы переживают, что нейросети отберут у них работу, тогда как другие считают, что это только поможет в креативном процессе. Программисты и художники осваивают prompt engineering — искусство подбора текста для получения более точных результатов генерации, — и делятся интересными запросами и не менее интересными результатами.



Как работают диффузионные модели?
Модели диффузии — это итеративные модели, которые принимают на вход случайный шум. Для начала рассмотрим самую базовую модель диффузии DDPM (Denoising Diffusion Probabilistic Model), представленную в работе Ho et al. Эта модель обучается пошагово на выборке из сотен тысяч изображений, где на каждом шаге к изображению из выборки применяется случайный шум некоторой известной силы, а модель учится обращать это зашумление, таким образом повышая качество изображения. Если мы итеративно применим таким образом обученную модель к картинке из полностью случайного шума, на каждом шаге обращая «слабое» зашумление, модель сможет сгенерировать полностью новое изображение, постепенно избавляя его от случайного шума — при помощи обратной диффузии.

Иллюстрация базового процесса диффузии (из туториала CVPR 2022)
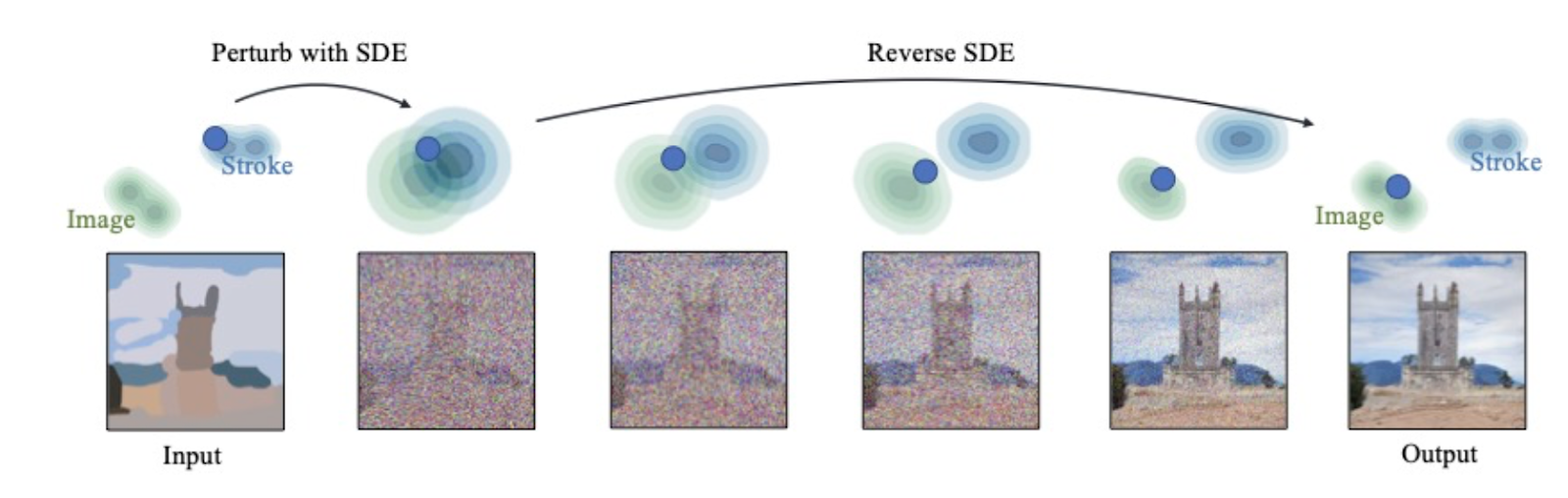
Случайный шум, из которого генерируется изображение, можно сочетать с условием — требованием к результату, выраженным текстом или другим изображением-примером. Для начала рассмотрим пример из статьи SDEdit, где пользователь указывает нейросети рисунок, состоящий из крупных мазков. Этот рисунок далее зашумляется до той степени, когда его нельзя отличить, например, от зашумленной фотографии, а после применяется итеративный процесс обратной диффузии, который и восстанавливает изображение высокого качества на основе предоставленного рисунка.
Другой способ направить генерацию к нужному результату — обуславливание модели текстом. Для этого используются языковые модели, обученные на парах изображений и подписей к ним, которые способны понимать смысл изображений и текстов одновременно. Примером такой модели является CLIP (Contrastive Language — Image Pre-training), выпущенная OpenAI. Эта модель способна переводить изображения и тексты в общее латентное векторное пространство (где вектор — это просто столбец некоторых значений). В этом пространстве становится, к примеру, возможным находить ближайшие изображения к некоторому текстовому запросу, так как это просто алгебраическая операция над векторами.
Модель латентной диффузии (Latent Diffusion), представленная в 2021 году, обуславливает модель на векторное пространство текстов, чтобы генерировать изображения из направленного шума. Эта модель использует свойства общего латентного пространства текстов и изображений. По такому принципу работают Stable Diffusion, Imagen и другие большие нейросети text-to-image.
Другим важным приемом, улучшающим качество генерации, используемым при обучении обусловленных моделей диффузии, является classifier free guidance. Говоря простым языком, чем выше значение параметра classifier free guidance, тем больше результат напоминает текстовый запрос, что часто выражается в меньшей вариативности результатов.
Проблемы диффузионных моделей
Конечно, модели диффузии не являются универсальным решением для задачи генерации изображений. Они все еще подвержены тем же проблемам, что и GAN — на первый взгляд реальные изображения обладают значительными недостатками — сгенерированные люди могут иметь больше пяти пальцев или 32 зубов. Также эти модели достаточно плохо умеют генерировать текст на изображениях и даже изобретают свой собственный «язык».
Художники обвиняют Midjourney и Stability AI (компанию, разрабатывающую Stable Diffusion) в нарушении авторских прав при подготовке данных для обучения — они утверждают, что компании скачали изображения из интернета без согласия художников и должной компенсации. Также активно поднимается вопрос о том, что генеративные сети, и Stable Diffusion в том числе, усугубляют негативные стереотипы о расе, гендере и других социальных проблемах, так как они обучаются на заведомо смещенных данных, полученных из интернета.

Как попробовать бесплатно
В отличие от многих предыдущих разработок в области компьютерного зрения, которые были часто доступны только программистам, новые технологии в области диффузионных сетей чаще всего могут попробовать все желающие. Общий тренд на открытое программное обеспечение и публикацию демо-версий нейросетей позволяет таким стартапам, как Hugging Face, агрегировать многие версии моделей, например, Stable Diffusion 2.1. Они же разрабатывают библиотеку diffusers, которая призвана упростить использование моделей в коде.
Сервис Google Colab позволяет запускать код на GPU и TPU, поэтому многие энтузиасты используют его для публикации своих версий модели, к примеру, модель Disco Diffusion Warp, которая способна изменять стиль видео.
Появляются и удобные интерфейсы к моделям. Так, нейросеть MidJourney имеет бесплатную пробную версию на несколько десятков генераций, чего достаточно, чтобы попробовать модели text-to-image. OpenAI также предоставляет пробный доступ к модели DALL·E 2.
Что дальше
Можно уверенно сказать, что мы переживаем золотую эпоху нейросетевой генерации изображений. Сообщество с нетерпением ждет будущих продуктов компании Google, выпустившей закрытую для общего доступа диффузионную модель Imagen и большое количество статей на тему редактирования и генерации изображений, в том числе и при помощи других технологий искусственного интеллекта.
Появляются новые стартапы в области создания и редактирования изображений, которые успешно конкурируют с такими гигантами как OpenAI или Google. Новые статьи про диффузионные модели выходят почти еженедельно, а область их применения сегодня не ограничивается перечисленными задачами 2D-компьютерного зрения — они применяются в задачах medical imaging, генерации видео и 3D по тексту.
Читать далее:
Тайна красных полос на спутнике Юпитера раскрыта
Найдена «невозможная» планета. Она бросает вызов современной науке
Загадочным шестиугольным «сотам» в соляных пустынях нашли объяснение