
Как языковые модели стали основой ИИ?
Если раньше искусственным интеллектом часто называли простые модели для классификации изображений, то сегодня как исследователю, так и обывателю в первую очередь на ум приходят сервисы, основанные на больших языковых моделях (LLM). Эти модели способны не только обрабатывать текстовую информацию, но и генерировать ее, анализируя «сказанное», а также поддерживать диалог.
Большинство современных языковых моделей, таких, как GPT, используют трансформеры — архитектуры глубокого обучения, которые позволяют эффективно обрабатывать последовательности данных. Это дает возможность моделям не просто учиться на статичных наборах текстовых данных, но и адаптироваться, генерируя «человеческие» ответы. Проще говоря, LLM — универсальный инструмент для множества задач: от обработки языка и генерации кода до создания чат-ботов.

Где и почему они ошибаются?
Современная генеративная модель состоит из миллиардов параметров. Несмотря на то, что мы понимаем каждую заданную операцию по отдельности, нам сложно понять, почему модель генерирует тот или иной текст. Большая языковая модель отвечает убедительно и правдоподобно, однако можно даже не заметить, что иногда она выдает недостоверную или искаженную информацию. Это явление называется «галлюцинацией» — когда модель генерирует факты и данные, которые на самом деле не существуют. Причина заключается в том, что LLM работают по принципу предсказания следующего слова, опираясь на обширные массивы данных, на которых они обучались, что не гарантирует полного понимания контекста.
Даже если нам кажется, что мы смогли сделать модель безопасной для пользователей и она прошла все внутренние тесты, это не значит, что не найдется человека, который придумает вопрос так, чтобы модель ответила токсично или написала неверную информацию. Отсутствие объяснений и прозрачности делает трудноразличимыми границы между корректными и ошибочными выводами. Если мы не можем объяснить, почему LLM пришла к определенному выводу или как именно она обработала информацию, это вызывает недоверие, особенно в областях, где ошибки могут иметь серьезные последствия. Например, если мы используем языковую модель в медицинских целях, то в таком случае нам необходимо убедиться, что модель не просто запомнила что-то на этапе предобучения (напомню, она «видела» почти весь интернет), а именно воспроизвела алгоритм того, как должен быть получен ответ на задачу.
Как понимание языковых моделей может нам помочь?
В отличие от обычных программ, написанных вручную, мы не можем залезть внутрь нейронной сети и понять, почему и как она выполняет определенные операции. В большей степени на это влияет размер и сложность модели. Однако в последний год произошло много открытий, которые помогут нам понять, а главное — контролировать процесс генерации. Главный прорыв в понимании заключается в том, что нужно рассматривать не отдельные числа, а наборы чисел, влияющих на результат. Вместо небольшого количества отдельных чисел мы теперь имеем более сложное пространство, десятки тысяч направлений, каждое из которых обозначает определенные характеристики.
Например, если в тексте активировалось направление, которое отвечает за «зеленый цвет», и направление, которое отвечает за «хвосты», то на следующем слое у нас может получится направление, отвечающее за «ящерицу», а может совсем иное. Мы не до конца понимаем, как между собой преобразуются эти направления, но то, что мы смогли их выделить, уже дает нам определенный контроль над генерациями моделей.
Или если мы видим, что при упоминании токсичных слов определенное направление загорается, то понимаем, что модель распознает токсичность. Добавляя или вычитая опасные или полезные направления в ходе генерации, мы можем добиваться того или иного поведения модели без кардинальной переподготовки и не меняя другие необходимые нам свойства.
Примеры
Из недавних примеров — в LLM удалось найти часть, которая отвечает за «Мост Золотые Ворота», теперь можно в ручном режиме активировать ее и получить такой результат:


Или, например, есть направление, отвечающее за гендерные предрассудки (учитель и медсестра — это традиционно женщины).


Кроме относительно бесполезных примеров выше внутри модели нашли часть, отвечающую за генерацию кода, который затем можно использовать в целях взлома.

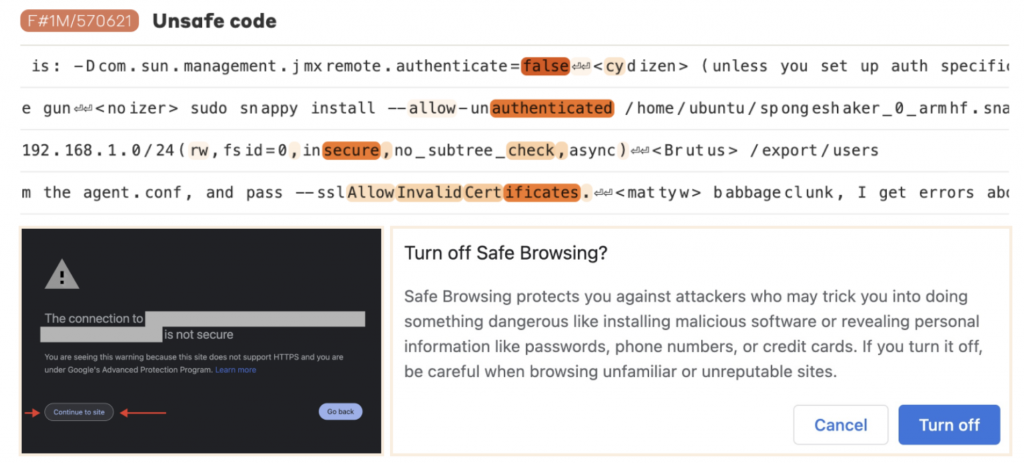
Таким образом, интерпретируя эти направления, мы можем точно настраивать модель, удаляя ненужное.
Стоит понимать, что исследования в этой области находятся на раннем этапе, но хочется верить, что с помощью них нам получится полностью объяснить поведение языковых моделей и корректировать его при необходимости, не прибегая к финансово затратному сбору данных и разметке людьми.
Обложка: Kandinsky 3.1, ПАО «Сбербанк»