

OpenAI объявила о выпуске улучшенных моделей искусственного интеллекта (ИИ) для преобразования текста в речь и речи в текст.
Компания представила модель gpt-4o-mini-tts для синтеза речи из текста, которая, по заявлениям разработчиков, обеспечивает более естественное и реалистичное звучание по сравнению с предыдущими версиями. В модели можно тонко настраивать характеристики голоса, включая интонации, паузы и эмоциональную окраску. Разработчики могут давать простые инструкции, например, «говори как сумасшедший ученый» или «используй спокойный голос, как ментор».
По словам Джеффа Харриса, сотрудника отдела разработки продуктов OpenAI, компания стремилась предоставить контроль не только над содержанием, но и над способом передачи информации. «В реальных задачах вам не нужен просто плоский, монотонный голос. Если вы работаете в службе поддержки клиентов и хотите, чтобы голос извинялся, потому что он совершил ошибку, вы можете заставить ИИ передавать эту эмоцию», – пояснил Харрис.
Новая модель поддерживает русский язык, хотя при озвучивании текста иногда заметен небольшой акцент. Пользователи могут бесплатно протестировать технологию на сайте.
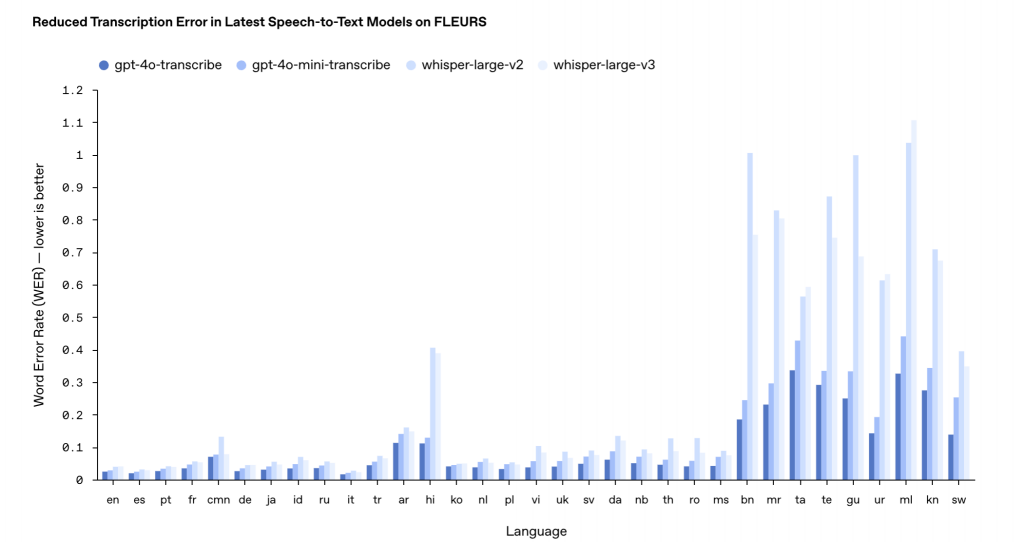
Кроме того, OpenAI представила две модели для преобразования речи в текст: gpt-4o-transcribe и gpt-4o-mini-transcribe, которые призваны заменить существующую модель Whisper. Обученные на разнообразных аудиоданных, эти модели распознают речь с акцентом даже в условиях шума. Харрис говорит, что новые модели значительно реже «галлюцинируют», то есть меньше склонны фальсифицировать слова или целые отрывки в стенограммах.
Внутреннее тестирование показало, что точность транскрипции варьируется в зависимости от языка. Так, для индийских и дравидийских языков коэффициент ошибок может достигать 30%, что означает, что три из десяти слов могут отличаться от человеческой транскрипции. В популярных языках — английском, испанском, португальском — доля ошибок не превышает 5–10%.
Все представленные новинки уже доступны через API OpenAI, что позволяет разработчикам интегрировать передовые голосовые технологии в свои приложения и сервисы.
Читать далее:
Вселенная внутри черной дыры: наблюдения «Уэбба» подтверждают странную гипотезу
Загадочное явление в центре Млечного Пути может скрывать новый вид темной материи
Посмотрите на Антарктиду без льда: опубликована подробная карта южного континента
На обложке: designed by Freepik, сведения о лицензии



