

У экспертов получилось в 1,5—2 раза ускорить обучение больших языковых моделей, что в перспективе поможет снизить стоимость и время разработки более умных и понятных человеку ИИ-помощников. Впервые для этих целей учёные использовали данные о том, как человек визуально воспринимает и читает текст.
Научные сотрудники Исследовательского центра в сфере ИИ Университета Иннополис представили новый способ повышения эффективности обучения с подкреплением на основе отзывов людей RLHF — ключевого метода для согласования больших языковых моделей с предпочтениями пользователей.
По словам учёных, основные проблемы современных методов RLHF — их высокая вычислительная стоимость и медленная сходимость из-за разреженности сигналов обратной связи: модель наград анализирует весь сгенерированный текст одной общей оценкой, не указывая, какие именно его части были хорошими или неудачными. Авторы исследования предложили использовать для решения этих проблем данные о взгляде человека, изучающего текст: на какие части текста он обращает внимание, в какой последовательности и как долго задерживает взгляд на каждой из них.
Карим Галлямов, программист-математик Лаборатории искусственного интеллекта в медицине Университета Иннополис: «Сбор большого набора данных о предпочтениях людей для обучения нейросетей — дорогостоящая процедура. Обычно исследователи собирают маленький набор данных и обучают модель наград, которую затем используют для дообучения основной модели. Модель наград предсказывает одно значение — награду — то, насколько ответ основной модели соответствует предпочтениям людей. Это малоинформативно, потому что множество факторов влияют на предпочтения, а при таком подходе мы пытаемся сжать их до одного числа. Недавно международные учёные представили подход с плотной наградой, когда награда распределяется между каждыми частями ответа модели на основе внимания самой модели — это даёт больше полезной информации в процессе дообучения основной модели. Мы же сделали шаг вперёд и стали использовать данные о взгляде человека при изучении текста, что более естественно».
Данные взгляда можно получить, если в основании монитора компьютера закрепить айтрекер — устройство для отслеживания взгляда и провести эксперименты с несколькими пользователями. Эти исследования дорогие, долгие и не позволяют быстро получать информацию при замене текста на новый. В таких случаях учёные используют модели предсказания взгляда человека, читающего текст, — на основе синтетических данных они рассчитывают награду по каждой части текста для использования в RLHF.
Научные сотрудники Исследовательского центра в сфере ИИ ИТ-вуза провели эксперименты на англоязычных текстах с языковыми моделями LLaMa и Mistral, в которых протестировали два метода интеграции взгляда. Первый применяет модели наград, изначально обученные с учётом спрогнозированных признаков человеческого взгляда. Второй — новый метод, предложенный авторами из Университета Иннополис. Он не меняет саму модель награды, а накладывается поверх неё и использует предсказания человеческого взгляда для распределения единой итоговой оценки по отдельным словам сгенерированного текста.
Эксперименты показали, что оба метода в 1,5—2 раза быстрее обучают модели по сравнению со стандартными подходами, но вариант исследователей — более адаптивный и простой, так как можно использовать любую модель наград без внутренних изменений в самой модели. В обоих случаях ускорение обучения достигается без ухудшения итоговой производительности языковой модели и сокращает время и ресурсы, необходимые для оптимизации параметров модели. При этом результаты универсальны — устойчивы для разных больших языковых моделей, наборов данных и алгоритмов обучения с подкреплением.
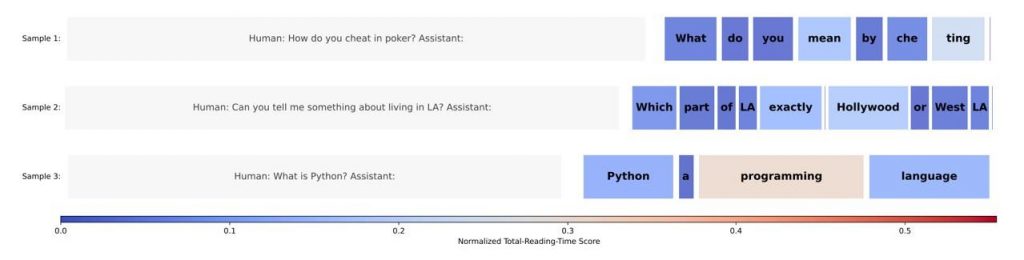
Распределение внимания человека между частями текста. Слева — вопрос, справа — части сгенерированного ИИ-моделью ответа: где цвет тёплее, туда смотрели чаще всего.
Илья Першин, руководитель Лаборатории искусственного интеллекта в медицине Университета Иннополис: «Исследование доказывает, что человеческий взгляд является значимым и ранее недооценённым сигналом в обучении ИИ-моделей. Использование данных взгляда позволяет создавать более эффективные и экономичные методы согласования языковых моделей. Это не просто ускоряет процесс, а делает его целенаправленнее, подобно тому, как учитель вместо “двойки” за работу указывает ученику на конкретные фразы, требующие доработки. Кроме того, наша работа показала, что данные взгляда человека могут быть заменены синтетическими, чтобы решить главные проблемы подобных исследований — острую нехватку информации о взгляде и сложность с получением новых данных».
Научные сотрудники отмечают, что текущее исследование они провели только для онлайн-методов RLHF — PPO, GRPO — и на английском языке. В будущем эксперты планируют изучить применимость подхода к офлайн-методам, например, DPO, а также расширить эксперименты на другие языки и модели.
Статья «Улучшение RLHF с помощью моделирования человеческого взгляда» (Enhancing RLHF with Human Gaze Modeling) опубликована в сборнике научных работ международной конференции по обработке естественного языка EMNLP. Её авторы — исследователи Лаборатории искусственного интеллекта в медицине Исследовательского центра в сфере ИИ Университета Иннополис Карим Галлямов, Иван Титов и Илья Першин.
Читать далее:
Вселенная внутри черной дыры: наблюдения «Уэбба» подтверждают странную гипотезу
Испытания ракеты Starship Илона Маска вновь закончились взрывом в небе
Сразу четыре похожих на Землю планеты нашли у ближайшей одиночной звезды



