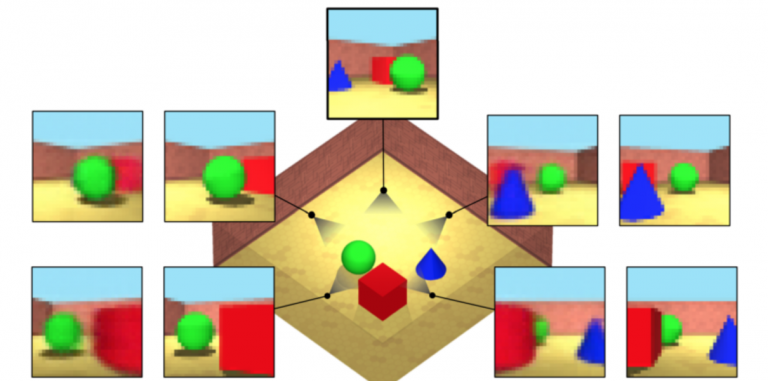
Новое исследование от британской компании DeepMind, которая принадлежит Google, показало, что глубокие нейронные сети теперь могут понимать и определять сцену в формате изображения, а затем «представлять» ее с любого угла, даже если никогда не видели его
Во время создания разработчики ориентировались на способности человека: скажем, если ему показать изображение насекомого с тремя лапками, то большинство интуитивно поймет, что, скорее всего, должна быть и четвертая лапка. С помощью практики мы можем научиться рисовать и понимать сцену под другим углом, принимая во внимание перспективу, тень и другие визуальные эффекты.

«Ну как бы э-э-э»: почему Google Duplex — не прорыв
Технологии
Команда DeepMind, во главе с Али Эслами, разработала программное обеспечение на основе глубоких нейронных сетей с теми же возможностями—по крайней мере, для упрощенных геометрических сцен. Учитывая несколько «снимков» виртуальной сцены, программное обеспечение, известное как генеративная сеть запросов, использует нейронную сеть для создания компактного математического представления этой сцены. Затем он использует это представление для визуализации изображений с новых углов
«Один из самых удивительных результатов [был], когда мы увидели, что он может предсказывать такие вещи, как перспектива и окклюзия, освещение и тени», — отметил Эслами. Однако как программисты не пытались жестко закодировать новые законы физики в программное обеспечение, оно могло «эффективно обнаружить эти правила, глядя на изображения».



