

Крис Саад, бывший глава отдела разработки продуктов в Uber, разработал новую платформу для оценки интеллекта искусственного интеллекта. Фреймворк основан на теории о том, что ИИ не является монолитной конструкцией. «Хайтек» рассказывает, почему платформа должна заменить стандартный тест Тьюринга и что это такое.
ИИ стал популярной темой за последние несколько месяцев после того, как OpenAI опубликовала диалоговый чат-бот ChatGPT. Пользователи протестировали его во многих различных областях, от написания стихов до кода и даже коммерческих предложений. Результаты его работы не только впечатляют, но и вызывают опасения.
Что такое тест Тьюринга?
Тест Тьюринга предложил Алан Тьюринг в статье «Вычислительные машины и разум», опубликованной в 1950 году в философском журнале Mind. Ученый задался целью определить, может ли машина мыслить. Сам тест должен был «раскусить» любой ИИ в попытке притвориться человеком. Но область искусственного интеллекта прошла долгий путь с момента появления теста более 70 лет назад.
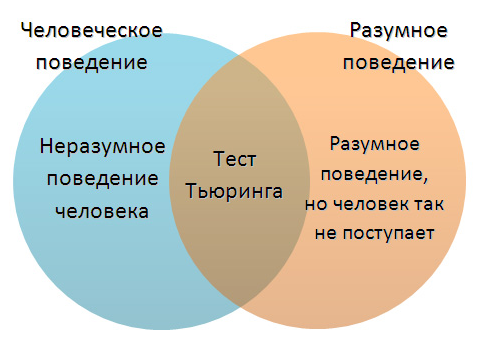
Идея проверки предполагала общение человека с другим, используя компьютерную программу в течение пяти минут, только в текстовом режиме. Если компьютер сможет обмануть как минимум 30% собеседников, тест считается пройденным. Эксперты общаются одновременно с живым человеком и роботом, находясь в разных комнатах и не видя друг друга. По окончании теста каждый из них должен сказать, кто из двух его собеседников был человеком, а кто — программой.
Когда его прошли впервые?
Его пытались пройти с 1960-х годов, и в 2014 году это удалось программе Eugene Goostman («Евгений Густман»), которая выдавала себя за 13-летнего мальчика по имени Евгений Густман из Одессы. Ей удалось убедить общавшихся с ней людей в том, что выдаваемые ею ответы принадлежат живому, реальному человеку. В прошлом году ИИ Google LaMDA также прошел тест Тьюринга.
В чем проблема теста?
Тест Тьюринга работает по упрощенной схеме «пройдено/не пройдено» и в значительной степени фокусируется на чате/лингвистических возможностях, которые являются лишь одним из аспектов человеческого интеллекта. Он игнорирует многие другие важные аспекты интеллекта, такие как решение проблем, творчество и социальная осведомленность. Кроме того, тест Тьюринга предполагает уровень интеллекта, подобный человеческому, который может не иметь значения или быть бесполезным для оценки ИИ.
Что такое «Теория множественного интеллекта»?
В 1983 году психолог Говард Гарднер утверждал, что интеллект представляет собой совокупность различных способностей, которые могут проявляться по-разному, и разделил их на восемь типов.
Гарднер выделил восемь различных типов интеллекта: по его словам, люди могут преуспеть в одной или нескольких из этих областей, и каждый тип интеллекта независим от других. Теория бросила вызов традиционному взгляду на интеллект как на единую фиксированную сущность и открыла новые возможности для изучения разнообразия человеческого познания. Хотя теория множественного интеллекта на протяжении многих лет подвергалась некоторой критике и спорам, она оказала значительное влияние на область психологии и образования. Так появилась «Теория множественного интеллекта».
Что предложили взамен и как это работает?
Крис Саад, бывший глава отдела разработки продуктов в Uber, назвал эту концепцию «идеальной в качестве основы для фреймворка классификации ИИ» и создал структуру классификации на ее основе. Она оценивает инструменты ИИ по нескольким измерениям: лингвистическо-вербальному, логико-математическому, музыкальному, зрительно-пространственному, телесно-кинестетическому, межличностному и внутриличностному интеллекту.
Для каждого измерения интеллекта схема предлагает шкалу от 1 до 5, где 1 — называется No Capability («неспособный»), а 5 — Self-agency («самостоятельный»). Первый уровень эквивалентен младенцу человека, а пятый — «сверхразуму», чей интеллект выше человеческих способностей.
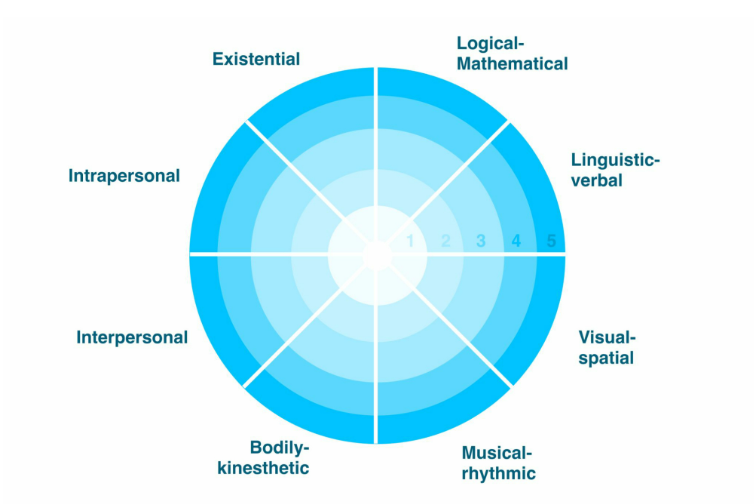
Сам фреймворк доступен по ссылке. Также Крис Саад создал простое визуальное представление для удобного использования.
Как справился ChatGPT ?
Согласно тесту, ChatGPT показывает третий уровень в двух измерениях: лингвистическо-вербальном и логико-математическом.
Это значит, что он генерирует и/или анализирует совершенно новые математические формулы и доказательства экспертного уровня на основе подсказок на обычном языке. Также он создает и/или анализирует совершенно новый письменный контент экспертного уровня на основе подсказок на естественном языке.
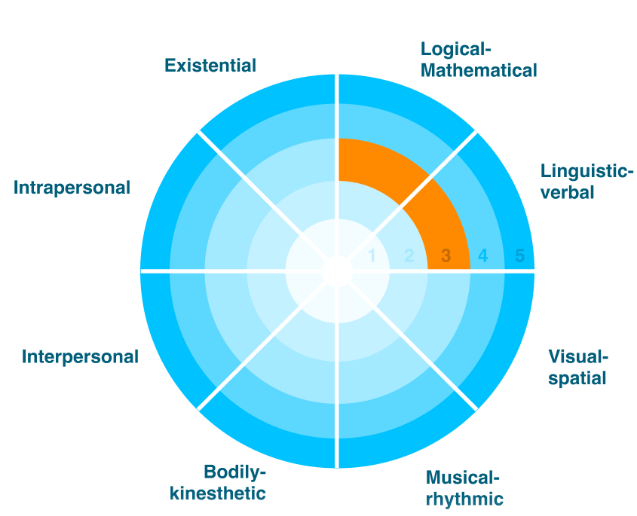
В остальных измерениях — музыкальном, зрительно-пространственном, телесно-кинестетическом, межличностном и внутриличностном — ChatGPT получил ноль или «не показал способностей в этой области».
Как справился DALL-E?
DALL-E — нейронная сеть, также авторства OpenAI, созданная при финансовой поддержке Microsoft, способная генерировать высококачественные изображения, исходя из текстовых описаний на английском языке, тоже проверили с помощью новой системы.
Согласно тесту, DALL-E показывает третий уровень в одном измерении: зрительно-пространственном. Это значит, что ИИ генерирует и/или анализирует сложные визуальные сцены. При анализе может отслеживать объекты, несмотря на окклюзию или другие визуальные шумы. Способен прогнозировать и отслеживать сложные движения. При генерации можно создавать совершенно новые статические визуальные представления на основе подсказок на обычном языке.
В лингвистическо-вербальном, логико-математическом, музыкальном, телесно-кинестетическом, межличностном и внутриличностном интеллекте он показал нулевой уровень.
Читать далее:
Форма Млечного Пути совсем не такая, как мы считали все это время, выяснили ученые
Две суперземли нашли на краю обитаемой зоны: на одной из них комфортная температура
Найдена черная дыра, которая уничтожает звезду рекордно близко к Земле